Machine Learning vs Reinforcement learning. What is the difference?
In Machine learning one of the most important parts is your data. In some cases, however, you can generate data on the fly. If so, you might want to consider Reinforcement learning. This is a technique that lets the model make predictions in a secure environment. After every prediction, the model receives a reward. A positive reward if it was a good prediction, a negative one if the prediction was incorrect. By giving this reward, the model learns what a good prediction is. Then the model makes the next prediction.
Reinforcement learning is in my opinion easiest explained when compared to teaching a dog. When you say "sit" and the dog actually sits we give him a cookie (reward), if the dog runs away we shout (punish), and if he does nothing he doesn’t get anything or maybe an angry stare (small punishment). We keep repeating this process until the dog acts as we want him to.
Reinforcement learning works the same way. After training in a simulation, we can release the model into the real world.
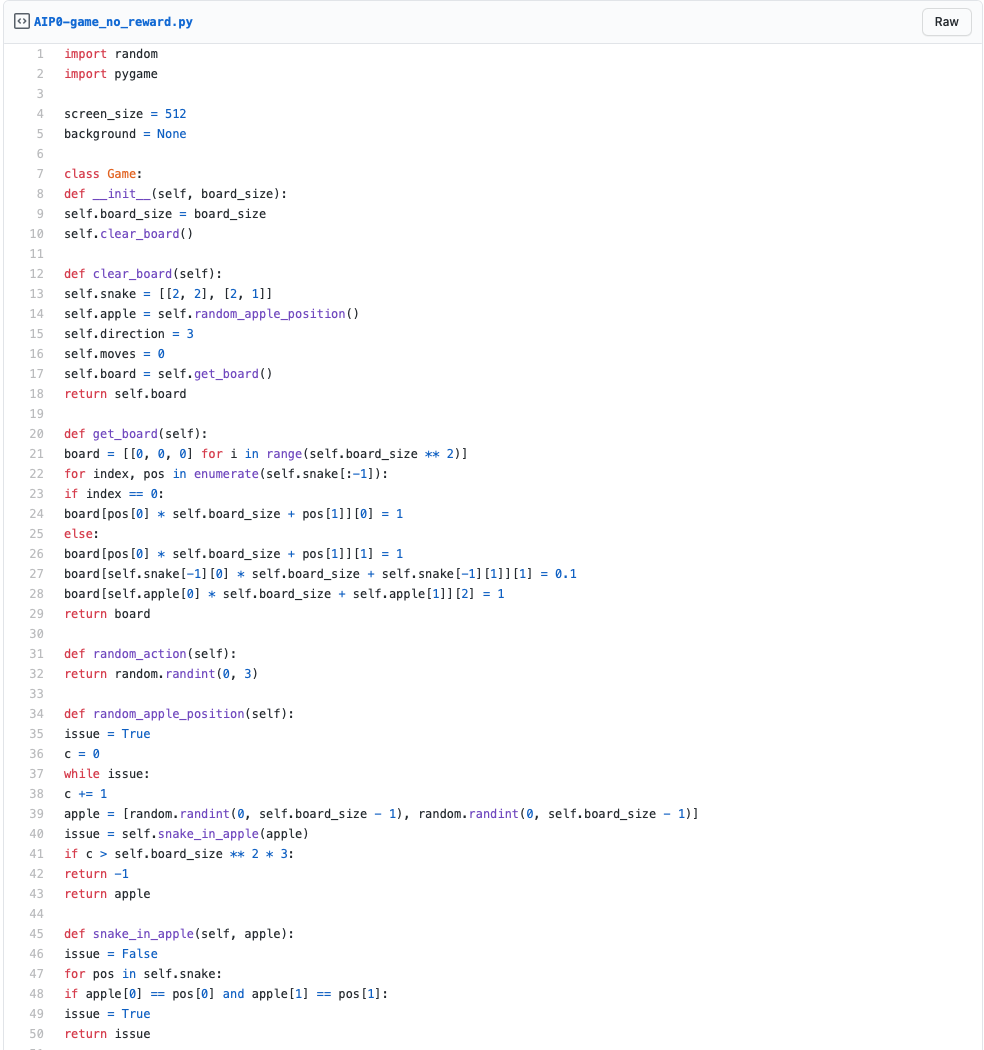
Creating Snake
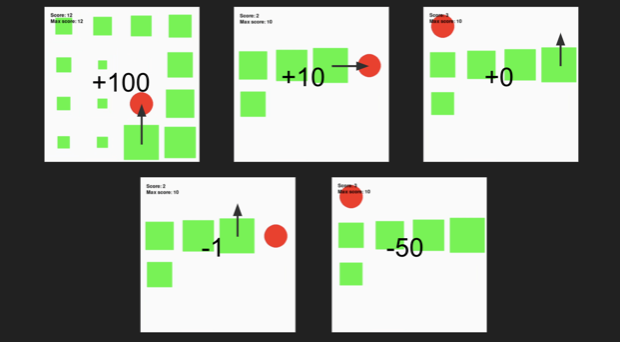
Let's have a look at this in practice with the game Snake. First, we need to create a game that isn't too hard. You start with a 2-long tile snake in the center of your board and an apple on different random spots. With every tick, you move 1 tile and that can result in 4 things:
Pick-up the apple
Go off the board
Hit yourself
Nothing
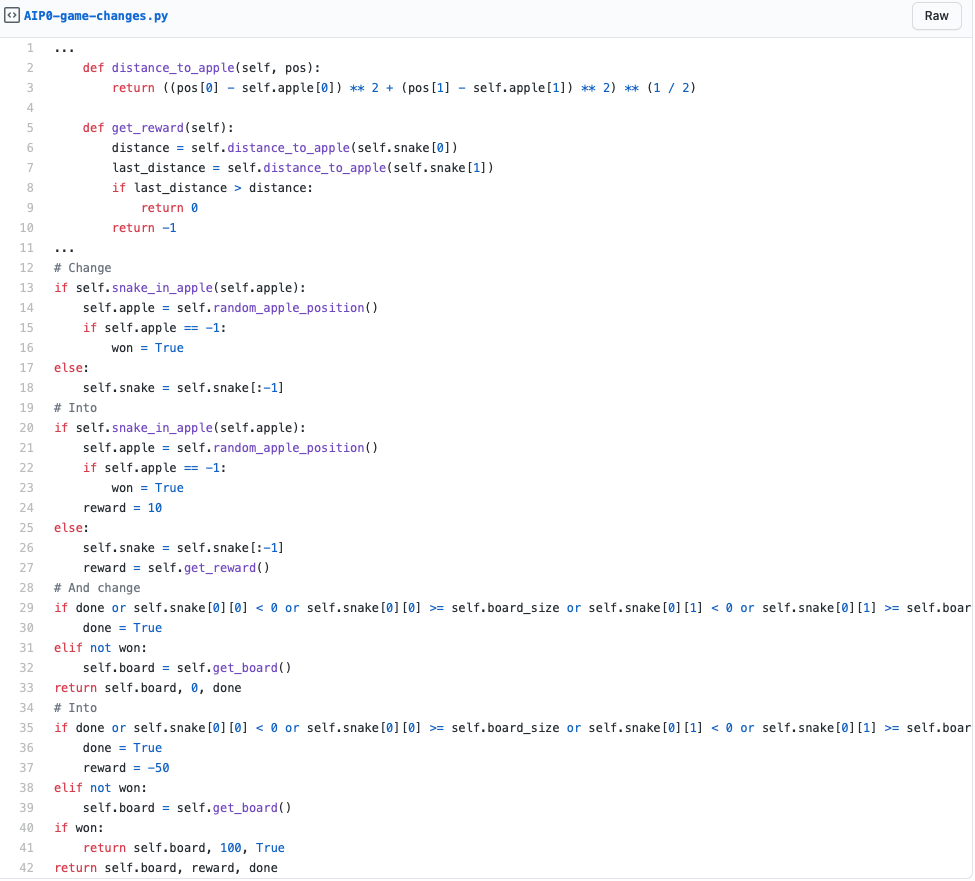
If you pick up the apple, a new apple appears in any random empty spot and your snake grows with one tile. You win the game if your snake is as long as the board.
If you go off the board or hit yourself, you die and start over.
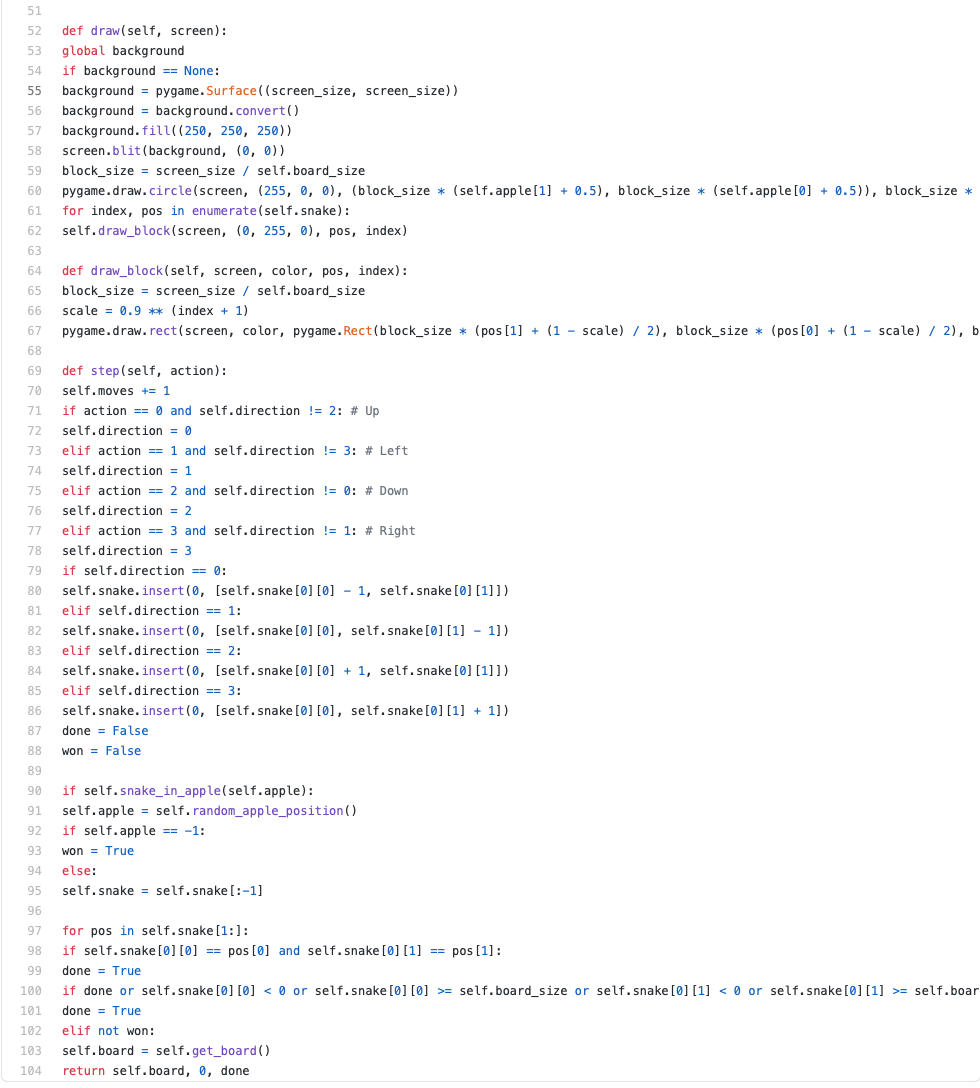
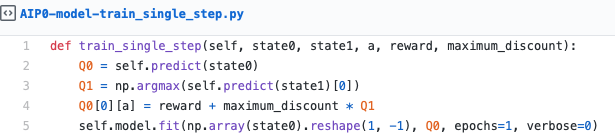
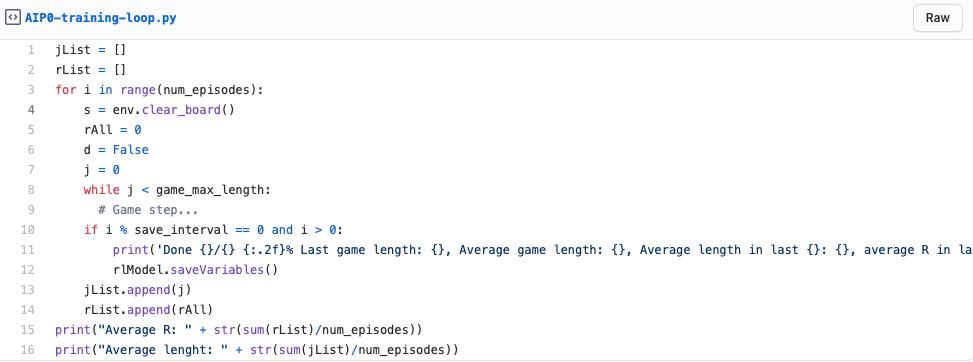
Then follow the actual training. We have two loops, one that repeats for every game we will be playing and one that loops until the game is over (either won or died). After 100 games, we save the model and print its current results.
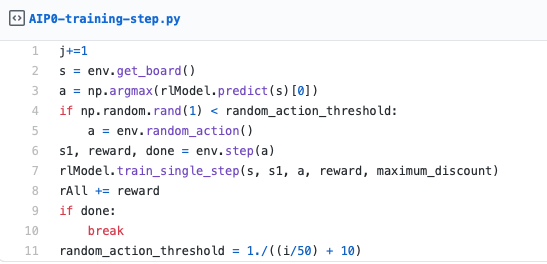
Sometimes randomly pick another action (so we can learn more obscure strategies)
Take the action and retrieve the reward
Train on how well the action was. This is based on the reward.
Repeat until the game is over
Going back to the example of teaching the dog, this is a very similar process. The dog will try some “random” things until it receives a reward and he will try to do better next time.
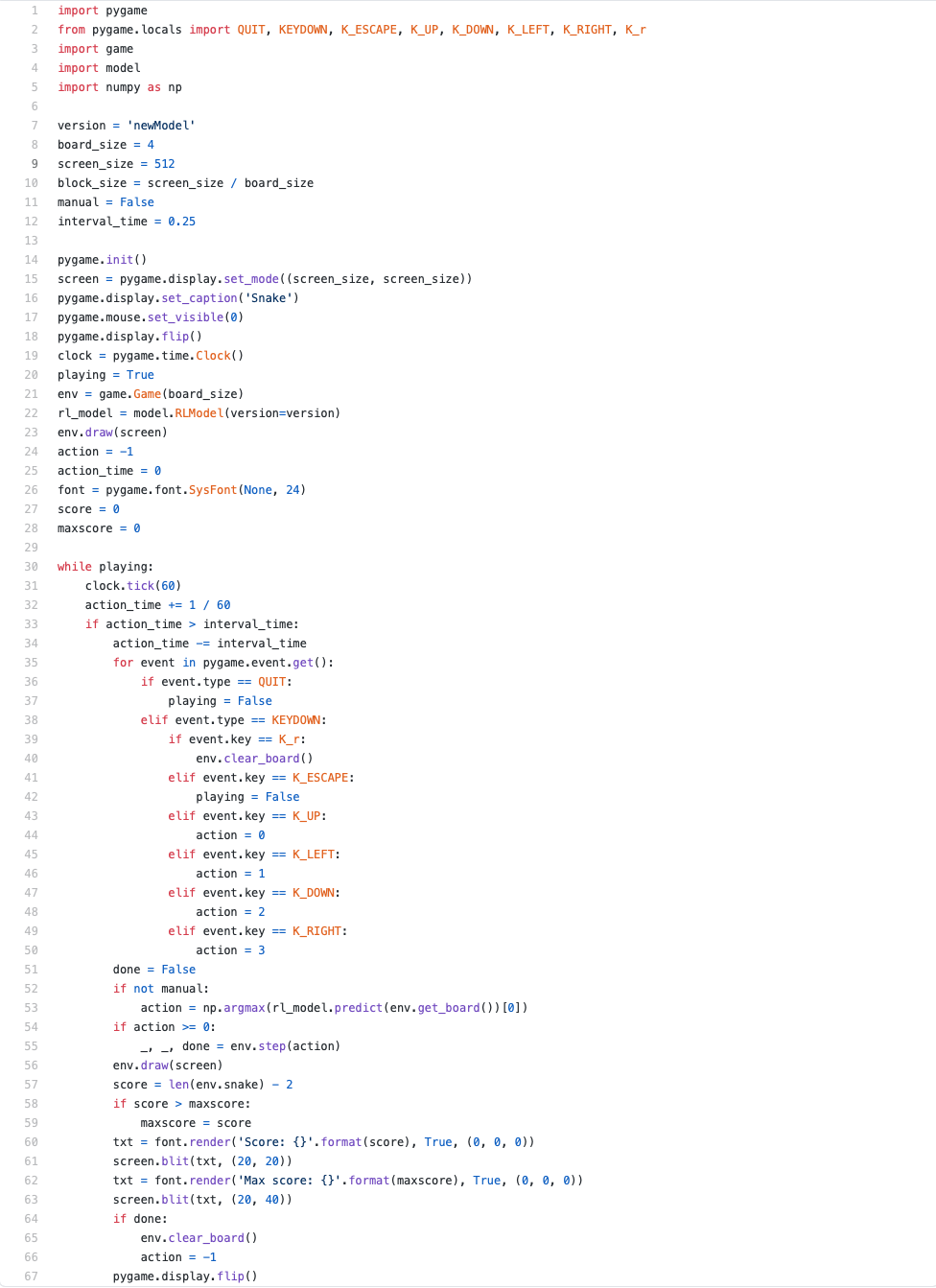
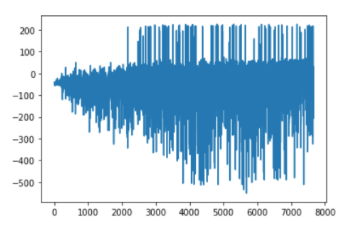
After training for ~7500 games, we can see that the model has already won the game a few times.
What's next
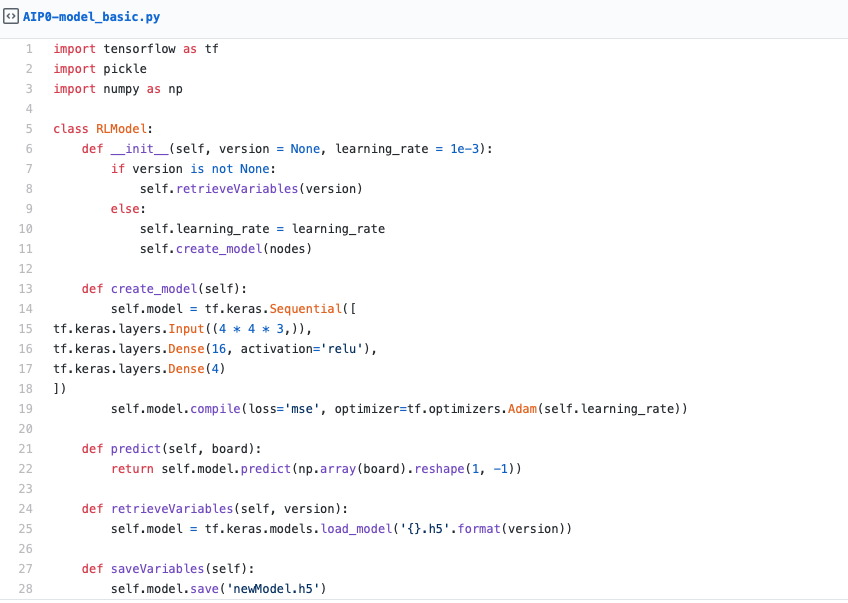
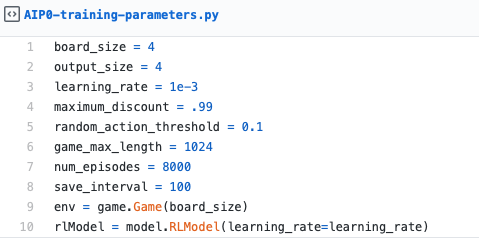
The next thing you should try is to increase the board size and see if you can retrain the snake on a bigger board. Maybe you’ll notice that the model and learning rate are not ideal. You might even want to change the reward. Try out a few things and find out if the model is able to beat it. Then you can increase the size even further or try it out on a different game.
Thank you for reading. You can find the source code on GitHub, or check out my YouTube video. Let me know if you encounter any issues. If you want more information about RL, there are some great articles about it online.